



JavaScript 中的结构化错误处理依赖于 throw 和 try/catch,开发人员将在其中声明一个错误,并将控制流传递至处理错误的程序的某一部分。当某一错误被引发时,Chakra,即 Internet Explorer 中的 JavaScript 引擎将捕获引发该错误的调用链,这一过程也被称为调用堆栈。如果被引发的对象是一个 Error(或者是一个函数,且其原型链将导致 Error),那么 Chakra 将创建一个堆栈跟踪,即可人工读取的调用堆栈列表。该列表将被表示为一种属性,即 Error 对象中的 stack。stack 包含错误消息、函数名称和该函数的源文件位置信息。这些信息将有助于开发人员了解所调用的函数,甚至查看错误的代码行,从而迅速诊断缺陷。例如,这些信息可能表明传递至函数的某一参数为空,或为无效类型。
让我们一同来查看一个简单的脚本,并以此展开深入讨论。该脚本试图计算 (0, 2) 和 (12, 10) 两点间的距离:
复制代码
代码如下:
(function () {
'use strict';
function squareRoot(n) {
if (n < 0)
throw new Error('Cannot take square root of negative number.');
return Math.sqrt(n);
}
function square(n) {
return n * n;
}
function pointDistance(pt1, pt2) {
return squareRoot((pt1.x - pt2.x) + (pt1.y - pt2.y));
}
function sample() {
var pt1 = { x: 0, y: 2 };
var pt2 = { x: 12, y: 10 };
console.log('Distance is: ' + pointDistance(pt1, pt2));
}
try {
sample();
}
catch (e) {
console.log(e.stack);
}
})();
该脚本中包含一个缺陷,其未调整组件间的差异。因此,对于某些输入而言,
pointDistance 函数将返回错误的结果;而在其他情况中,该脚本将导致错误发生。为了理解堆栈跟踪的含义,让我们一同来查看 F12 开发人员工具中的错误,并查看其脚本选项卡:
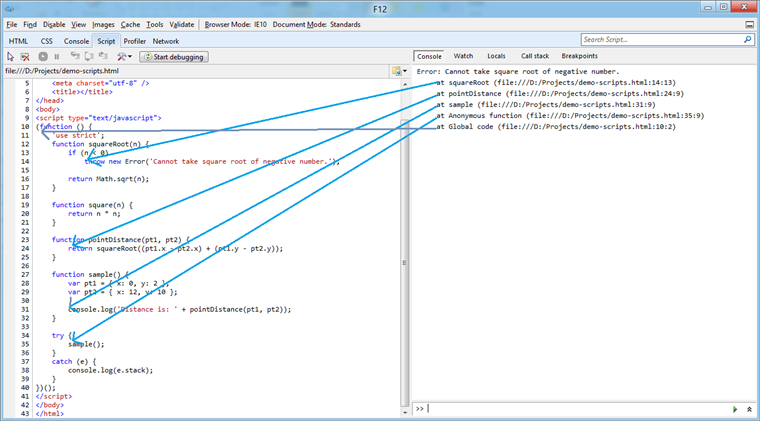
堆栈跟踪将转储至 catch 子句中的控制台,由于其位于堆栈的顶部,因此起源于 squareRoot 函数的错误将变得显而易见。为了调试这一问题,开发人员无需深入查看堆栈跟踪;系统已违反 squareRoot 的前置条件,而且只需查看堆栈的上一级,原因将变得十分明了:squareRoot 调用内的子表达式自身应该为 square 的参数。
调试过程中,stack 属性将有助于识别用于设置断点的代码。请记住:您还可使用其它方法来查看调用堆栈:例如,如果您将脚本调试程序设置为“捕获异常即中断”的模式,那么您可使用该调试程序来检查调用堆栈。对于部署的应用程序,您可考虑在 try/catch 内合并问题代码,以捕获失败的调用,并将其记录于服务器中。随后,开发人员可查看调用堆栈,以隔离问题区域。
此前,我曾注意到被引发的对象必须为 Error 或通过其原型链导致 Error。这是有意而为之;JavaScript 可支持引发任何对象,甚至包括作为异常的基元。尽管系统可捕获和检查所有这些对象,但是它们的全部用途并非包含错误或诊断信息。因此,引发过程中仅将更新错误的 stack 属性。
即便对象为 DOM 异常,它们也不包含可导致 Error 的原型链,因此它们将不包含 stack 属性。在某些应用场景中,您需要执行 DOM 操作,并希望暴露 JavaScript 兼容的错误,那么您可能希望在 try/catch 数据块内合并您的 DOM 操作代码,并在 catch 子句中引发一个新的 Error 对象:
复制代码
代码如下:
function causesDomError() {
try {
var p = document.createElement('p');
p.appendChild(p);
} catch (e) {
throw new Error(e.toString());
}
}
然而,您可能将考虑是否要使用该模式。这可能是最适用于实用工具库开发的模式,特别是在您考虑代码的意图是否为隐藏 DOM 操作或简单地实施某一任务的时候。如果其目的为隐藏 DOM 操作,那么合并操作并引发
Error 可能是我们需要选择的正确方式。
性能注意事项
堆栈跟踪的构造始于错误对象被引发之时;构造堆栈跟踪需要查看当前执行堆栈。为了防止遍历特大堆栈过程中出现性能问题(甚至可能出现的递归堆栈链),默认情况下,IE 仅将收集前十位的堆栈帧。然而该设置可通过将静态属性 Error.stackTraceLimit 设置为另一数值而得以配置。该设置是全局性的,而且必须在引发错误之前 进行变更,否则其将对堆栈跟踪无效。
当某一堆栈是由异步回调(例如 timeout、interval 或 XMLHttpRequest)生成,那么异步回调(而非由异步回调创建的代码)将位于调用堆栈的底部。这将对跟踪有问题的代码产生某些潜在影响:如果您对多个异步回调使用相同的回调函数,那么您将难于通过单独检查而确定是哪一回调产生了错误。让我们对此前的示例稍作修改,我们将避免直接调用 sample(),而是将其放入超时回调:
复制代码
代码如下:
(function () {
'use strict';
function squareRoot(n) {
if (n < 0)
throw new Error('Cannot take square root of negative number.');
return Math.sqrt(n);
}
function square(n) {
return n * n;
}
function pointDistance(pt1, pt2) {
return squareRoot((pt1.x - pt2.x) + (pt1.y - pt2.y));
}
function sample() {
var pt1 = { x: 0, y: 2 };
var pt2 = { x: 12, y: 10 };
console.log('Distance is: ' + pointDistance(pt1, pt2));
}
setTimeout(function () {
try {
sample();
}
catch (e) {
console.log(e.stack);
}
}, 2500);
})();
一旦执行该代码段,您将发现堆栈跟踪将出现稍许延迟。此时,您将同时发现堆栈底部并非全局性代码
Anonymous function。事实上,这并非同一匿名函数,而是传递至 setTimeout 的回调函数。由于您丢失了与挂起回调有关的上下文,因此您可能无法确定调用回调的内容。如果在某一应用场景中,系统注册了某一回调来处理许多不同按钮的 click 事件,那么您将无法分辨注册将引用哪一回调。话虽如此,这一限制作用毕竟有限,因为在大多数情况中,堆栈顶部可能将突出显示问题区域。
观看体验演示
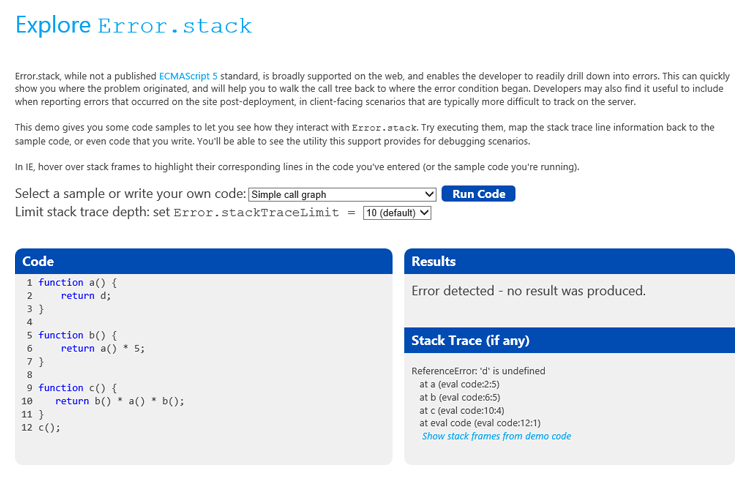
了解 Windows 8 Consumer Preview 中 IE10 的使用情况。您可在 eval 的上下文中执行代码,如果发生错误,您便可检查出该错误。如果您在 IE10 内运行代码,由于您可将错误代码行悬停于堆栈跟踪中,因此您也可突出显示您的代码行。您可自行将代码输入到代码区域,或者从列表中的数个示例中进行选择。此外,您还可在运行代码示例时设置 Error.stackTraceLimit 值。
如欲查看参考材料,请浏览有关 Error.stack 和 stackTraceLimit 的 MSDN 文档。

友情提示:垃圾评论一律封号 加我微信:826096331拉你进VIP群学习群